NodeJS et base de données
Introduction
Dans le laboratoire précédent, nous avons stocké les données dans des variables. Dans un souci de persistance évident, cette approche est à éviter pour une application en production. Vous devrez donc rapidement vous tourner vers une base de données. Nous allons voir ici comment interagir avec elle.
Pré-requis
Dans ce laboratoire, nous utiliserons Docker pour utiliser une base de données sans installation compliquée. Pour l’installation de Docker (si ce n’est pas déjà fait), référez-vous au document à ce sujet sur Moodle.
Ce laboratoire s'appuie sur le laboratoire précédent. Reprenez le code et modifiez-le directement (ou faites une copie si vous désirez garder une copie de chaque laboratoire.)
Initialisation d’une base de données et connection
Pour illustrer une utilisation de la base de données, nous allons utiliser PostgreSQL.
Ce que nous allons voir peut être appliqué à n’importe quelle base de données : MySQL, MariaDB, Cassandra, Mongo, SQLite, etc.
Pour commencer, on va préparer la base de données. Ouvrez un terminal et exécutez la commande suivante :
docker run --name postgres -e POSTGRES_PASSWORD=password -e POSTGRES_USER=john -e POSTGRES_DB=exercices -p 5432:5432 --rm -d postgres
Attendez quelques secondes que la base de données soit prête. La base de données est accessible via n’importe quel IDE pouvant accéder à une base de données (DBeaver, DataGrip, VSCode, etc). Voici les informations dont vous aurez besoin :
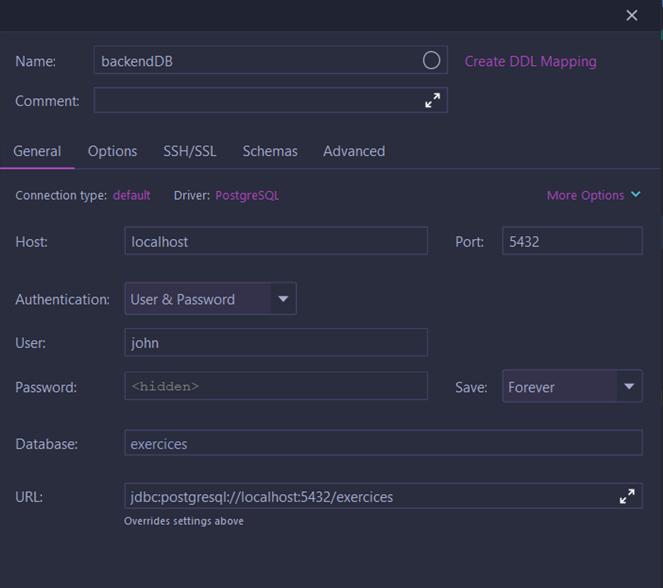
- Utilisateur : john
- Mot de passe : password
- Adresse : localhost (ou 127.0.0.1)
- Port : 5432
- Base de données : exercices
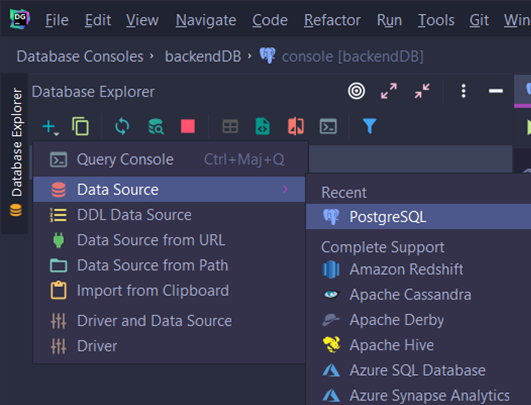
Voici un exemple avec DataGrip. Dans Data explorer, choisissez + et sélectionnez Data source :
Ensuite, entrez les informations données plus haut dans le formulaire (vous pouvez choisir le nom que vous voulez, cela n’a aucune importance) :
Différence entre pool et client
Dans certains frameworks, dont celui utilisé en exemple, on utilise le terme "pool" et "client". La différence est importante surtout si vous faites plusieurs opérations dans une transaction. Un client est une connexion vers la base de données. Quand vous faites plusieurs opérations avec un même client, c’est équivalent à faire une requête avec plusieurs instructions séparées par un ";". C’est également obligatoire si vous désirez récupérer une information pour l’utiliser dans une opération par la suite. Une pool sert à récupérer un client disponible et à le libérer (c’est-à-dire qu’il sera marqué comme libre) pour qu’il puisse être utilisé à nouveau. Il faut donc toujours veiller à libérer le client lorsque l’on a fini.
Le module pg permet de demander à une pool d’exécuter une requête. En réalité, il s’agit d’une facilité pour faire en une opération les étapes suivantes :
- Acquisition d’un client
- Exécution de la requête et récupération du résultat
- Libération du client
Il est donc important de bien utiliser un client et non une pool pour effectuer une série d’opérations d’une transaction.
Connection à la base de données via NodeJS
Maintenant, on va installer le driver (sous forme de module) qui permet de faire des requêtes facilement à la base de données. Pour cela, on utilise la commande suivante :
npm i pg
Première chose à faire : créez un fichier database.js dans database.
Ce fichier permettra d’avoir un pool de connexions.
L’avantage d’utiliser un tel système est qu’une connexion peut être réutilisée au lieu d’en recréer une nouvelle.
Dans ce fichier, vous ajoutez ce code :
import pg from "pg";
const pgPool = new pg.Pool({
user: 'john',
host: 'localhost',
database: 'exercices',
password: 'password',
port: 5432
});
/* ----- Deuxième partie ----- */
export const pool = {
query: async (query, params) => {
try {
return await pgPool.query(query, params);
} catch (e) {
console.error(e);
throw e;
}
},
end : () => {
return pgPool.end();
}
};
/* ----- Troisième partie ----- */
// Si nous fermons notre processus, nous fermerons automatiquement toutes les connexions ouvertes à la base de données
process.on("exit", () => {
pgPool.end().then(() => console.log("pool closed"));
});
Dans la première partie du code, nous instancions une pool avec les informations relatives à la base de données (l'addresse, le port, le nom d'utilisateur, etc).
Ainsi, nous obtenons une instance de notre libraire pg.
Est-ce une bonne idée de l'utiliser directement ?
Réponse

En utilisant directement une instance de pg.Pool partout dans notre code, nous couplons fortement notre code à la librairie.
Donc, au moindre changement, nous devrons modifier les multiples appels aux différentes méthodes de la librairie.
Pour palier ce problème, nous allons utiliser le "design pattern" Adapter.
Ainsi, dans la deuxième partie du code, nous allons créer un objet avec des méthodes fixes et dans ces méthodes, nous appelons les fonctions de notre instance de pg.
Notre code n'a presque plus aucun couplage avec la librairie et toute modification de celle-ci n'impactera que notre objet.
Dans la troisième partie, nous écoutons l'évènement de fin de processus. Lorsque celui-ci sera émis, nous fermerons notre pool et donc toutes les connexions associées.
Scripts
Script SQL
La pool est prête et vous pouvez l’utiliser dans votre application.
Nous allons peupler la base de données grâce à cela.
Créez un dossier appelé scripts et dedans créez deux autres dossiers : JS et SQL.
Ensuite, créez un fichier ./scripts/SQL/initDB.sql et collez le code suivant :
DROP TABLE IF EXISTS product CASCADE ;
CREATE TABLE product (
id int primary key generated always as identity,
name text,
price decimal
);
INSERT INTO product(name, price)
VALUES ('Playstation 5', 499.99),
('NVIDIA RTX 4090 FE', 1829),
('Xbox Series X', 499.99);
Script JavaScript
Maintenant, on va créer le script qui va lire les querys et les faire exécuter. Créez le fichier ./scripts/JS/initDB.js et ajoutez le code suivant :
import {readFileSync} from "node:fs";
import {pool} from "../../database/database.js";
const requests = readFileSync(
'./scripts/SQL/initDB.sql',
{encoding: "utf-8"}
);
try {
await pool.query(requests, []);
console.log("done");
} catch (e) {
console.error(e);
}
Ce que fait le code est assez simple:
- Il y a une fonction asynchrone qui lit le fichier SQL pour récupérer les requêtes
- Nous demandons à la pool d'exécuter l'ensemble des requêtes. Il s'agit juste d'une simplification pour demander un client SQL, lui faire exécuter les requêtes et libérer ce client.
- Nous attendons que les requêtes soient effectuées avec le mot clé
await. En cas de réussite, nous affichons "done" et en cas d'échec nous affichons le message d'erreur via la sortie standard prévue à cet effet.
Maintenant que le script est prêt, on va le rendre facile d’accès en l’ajoutant au fichier package.json.
À l’intérieur de ce fichier, ajouter la ligne suivante dans la partie scripts :
"initDB": "node scripts/JS/initDB.js"
Si on fait un npm run initDB le script crée la table et y ajoute les données.
Utilisation de notre base de données dans notre code
Ensuite, on va devoir mettre à jour les parties suivantes :
- les modèles (on va devoir utiliser notre base de données),
- les contrôleurs
- les routes (en effet, les fonctions vont devenir asynchrones).
Créez un fichier ./model/productDB.js et mettez le code suivant :
export const readProduct = async (SQLClient, {id}) => {
const {rows} = await SQLClient.query("SELECT * FROM product WHERE id = $1", [id]);
return rows[0];
};
Vous devriez TOUJOURS utiliser les requêtes paramétrées lorsque vous créez dynamiquement votre requête. Sans elles, vous vous exposez aux injections SQL !
Quand cela est fait, vous pouvez modifier le fichier ./controler/product.js et pour obtenir ceci :
import {pool} from "../database/database.js";
import * as productModel from "../model/productDB.js";
export const getProduct = async (req, res)=> {
try {
const produit = await productModel.readProduct(pool, req.params);
if (produit) {
res.send(produit);
} else {
res.sendStatus(404);
}
} catch (err) {
res.sendStatus(500);
}
};
Maintenant, la fonction du contrôleur est devenue asynchrone, ce qui permet d’utiliser le mot clé await.
Avec cet exemple et en vous inspirant du fichier ./controler/product.js, vous êtes capables de faire les trois fonctions manquantes : addProduct, updateProduct, deleteProduct (une solution sera proposée plus loin).
Enfin, dernière étape : mettre à jour les routes (dans ./routes/product.js) pour utiliser le nouveau contrôleur :
import Router from 'express';
import {
addProduct,
updateProduct,
getProduct, deleteProduct
} from "../controler/product.js";
const router = Router();
router.post("/", addProduct);
router.patch("/", updateProduct);
router.get("/:id", getProduct);
router.delete("/:id", deleteProduct);
export default router;
Vous avez maintenant un système qui marche complètement avec une base de données. Votre application n’est pas encore parfaite : il manque un système d’identification par exemple (nous verrons cela plus tard).
Exercice 1: écriture des modèles
Vous devrez essayer de transformer les autres 3 méthodes manquantes (createProduct, updateProduct et deleteProduct) en vous inspirant du code donné.
N'oubliez pas d’utiliser les requêtes paramétrées comme dans l’exemple.
export const readProduct = async (SQLClient, {id}) => {
const {rows} = await SQLClient.query("SELECT * FROM product WHERE id = $1", [id]);
return rows[0];
};
export const createProduct = async (SQLClient, {name, price}) => {
//TODO: essayer de renvoyer l'id du produit ajouté en utilisant l'instruction RETURNING de Postgres
};
export const deleteProduct = async (SQLClient, {id}) => {
//TODO
};
export const updateProduct = async(SQLClient, {name, price, id}) => {
//TODO
};
Exercice 2: écriture des controleurs
Vous devrez essayer de transformer les autres 3 méthodes manquantes (addProduct, updateProduct et deleteProduct) en vous inspirant du code donné.
import {pool} from "../database/database.js";
import * as productModel from "../model/productDB.js";
export const getProduct = async (req, res)=> {
try {
const produit = await productModel.readProduct(pool, req.params);
if (produit) {
res.json(produit);
} else {
res.sendStatus(404);
}
} catch (err) {
res.sendStatus(500);
}
};
export const addProduct = async (req, res) => {
//TODO: n'oubliez de renvoyer l'id du produit ajouté
};
export const updateProduct = async (req, res) => {
//TODO
};
export const deleteProduct = async (req, res) => {
//TODO
};
Exercice 3: écriture des routes
Vous devrez essayer de transformer les 3 autres routes manquantes
import Router from 'express';
import { getProduct } from "../controler/product.js";
const router = Router();
router.post("/", /*TODO*/);
router.patch("/", /*TODO*/);
router.get("/:id", getProduct);
router.delete("/:id", /*TODO*/);
export default router;
Solution
- ./model/productDB.js
- ./controler/product.js
- ./route/product.js
export const readProduct = async (SQLClient, {id}) => {
const {rows} = await SQLClient.query("SELECT * FROM product WHERE id = $1", [id]);
return rows[0];
};
export const createProduct = async (SQLClient, {name, price}) => {
const {rows} = await SQLClient.query("INSERT INTO product (name, price) VALUES ($1, $2) RETURNING id", [name, price]);
return rows[0]?.id;
};
export const deleteProduct = async (SQLClient, {id}) => {
return await SQLClient.query("DELETE FROM product WHERE id = $1", [id]);
};
export const updateProduct = async(SQLClient, {name, price, id}) => {
let query = "UPDATE product SET ";
const querySet = [];
const queryValues = [];
if(name){
queryValues.push(name);
querySet.push(`name = $${queryValues.length}`);
}
if(price){
queryValues.push(price);
querySet.push(`price = $${queryValues.length}`);
}
if(queryValues.length > 0){
queryValues.push(id);
query += `${querySet.join(", ")} WHERE id = $${queryValues.length}`;
return await SQLClient.query(query, queryValues);
} else {
throw new Error("No field given");
}
};
import {pool} from "../database/database.js";
import * as productModel from "../model/productDB.js";
export const getProduct = async (req, res)=> {
try {
const produit = await productModel.readProduct(pool, req.params);
if (produit) {
res.json(produit);
} else {
res.sendStatus(404);
}
} catch (err) {
res.sendStatus(500);
}
};
export const addProduct = async (req, res) => {
try {
const id = await productModel.createProduct(pool, req.body);
res.status(201).json({id});
} catch (err) {
res.sendStatus(500);
}
};
export const updateProduct = async (req, res) => {
try {
await productModel.updateProduct(pool, req.body);
res.sendStatus(204);
} catch (err) {
res.sendStatus(500);
}
};
export const deleteProduct = async (req, res) => {
try {
await productModel.deleteProduct(pool, req.params);
res.sendStatus(204);
} catch (err) {
res.sendStatus(500);
}
};
import Router from 'express';
import {
addProduct,
updateProduct,
getProduct, deleteProduct
} from "../controler/product.js";
const router = Router();
router.post("/", addProduct);
router.patch("/", updateProduct);
router.get("/:id", getProduct);
router.delete("/:id", deleteProduct);
export default router;
Informations sur la connexion à la base de données
Actuellement les informations sont stockées en dur dans l’application.
Ceci est une mauvaise approche du point de vue de la sécurité.
En effet, si un hacker venait à prendre possession de votre répertoire git, il aurait un accès à votre base de données.
Il existe pour cela les variables d’environnement qui permettent de créer des variables pour un processus.
Le problème de cette approche est qu’il faut préciser l’ensemble des variables à chaque fois que l’on lancera le processus.
Dans une phase de développement, cela peut s’avérer assez pénible. Dans une phase de production, si les serveurs redémarrent vous devrez relancer le processus manuellement.
Il existe une solution assez simple à ce problème qui consiste à créer un fichier .env à la racine de votre projet et d’y indiquer les informations nécessaires.
Les valeurs indiquées seront chargées par un paquet. Pour cela, utilisez la commande :
npm i dotenv
Et créez le fichier .env à la racine de votre projet.
Quand cela sera fait, référez-vous à la documentation du paquet dotenv pour comprendre comment compléter le fichier et comment utiliser les variables d’environnement.
Sachez juste qu’avec la configuration actuelle, vous n'aurez besoin de modifier que le fichier ./database/database.js.
Ce fichier .env ne doit donc pas être mis sur un git étant donné qu’il contient les informations secrètes.
Par contre, il est fortement conseillé de préciser quelque part (README.md, par exemple) qu’il faut un fichier .env et d’y indiquer quelles variables qu'il faut ajouter.
Voici un exemple d'un fichier .env:
PORT=3001
USERDB=john
Solution
import "dotenv/config";
import pg from "pg";
const pgPool = new pg.Pool({
host: process.env.HOSTDB,
user: process.env.USERDB,
password: process.env.PASSWORDDB,
database: process.env.DBNAME
});
export const pool = {
query: async (query, params) => {
try {
return await pgPool.query(query, params);
} catch (e) {
console.error(e);
throw e;
}
},
end : () => {
return pgPool.end();
}
};
process.on("exit", () => {
pgPool.end().then(() => console.log("pool closed"));
});
Accès complexe à la base de données : transaction
Quésako ?
Prenons un exemple pour mieux comprendre. Imaginons que nous avons une table Client et une table Achat (relation de type 1-N).
Nous souhaitons donner la possibilité aux visiteurs de notre site de pouvoir effectuer un achat tout en s'inscrivant en même temps.
Comment pourrions-nous faire ? La première idée serait:
- Faire un premier
INSERTdans la tableClientet récupérer l'id de ce dernier. - Faire un deuxième
INSERTdans la tableAchat. - Envoyer la réponse au client
L'idée peut sembler bonne au premier abord... Cependant, que se passerait-il si nous faisons l'étape 1 et qu'ensuite la base de données devienne indisponible (exemple: panne de courant) ? Dans ce cas, nous aurions uniquement l'opération 1 qui aurait été effectuée. Ce n'est pas vraiment ce que nous désirons. Nous voulons que tout réussisse ou que tout échoue.
Une transaction permet de réaliser un ensemble d'opérations en "une seule fois".
Ainsi, il est possible d'indiquer à la base de données que nous souhaitons réaliser une série d'opérations en un seul "bloc".
En cas de réussite toutes les opérations sont enregistrées. En cas d'échec, aucune opération n'est enregistrée.
Une transaction commence avec le mot clé BEGIN et se finit avec le mot clé COMMIT (pour demander d'enregistrer les informations) ou le mot clé ROLLBACK (pour ne pas enregistrer les informations).
N'oubliez pas que toutes les opérations d'une transaction devront être effectuées par un seul et unique client SQL !
Mise à jour de la base de données
Pour simuler un accès complexe, nous allons créer deux tables en plus de celle que nous avons déjà. L’idée est d’avoir une table "client" et "purchase" pour représenter les commandes. Dès lors, nous allons avoir besoin des transactions.
D’abord, nous allons améliorer notre fichier SQL pour ajouter ce qui manque. Ajoutez donc ces lignes :
DROP TABLE IF EXISTS client CASCADE;
CREATE TABLE client(
id integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
name varchar,
firstname varchar,
address varchar,
email varchar UNIQUE,
password varchar
);
INSERT INTO client (name, firstname, address, email, password)
VALUES ('Poirier', 'Tevin', '11, rue du Faubourg National 95150 TAVERNY', 'poirier@mail.com', 'motdepasse');
DROP TABLE IF EXISTS purchase CASCADE;
CREATE TABLE purchase (
product_id integer REFERENCES product(id) DEFERRABLE INITIALLY IMMEDIATE,
client_id integer REFERENCES client(id) DEFERRABLE INITIALLY IMMEDIATE,
quantity integer,
"date" date default NOW(),
PRIMARY KEY(product_id, client_id, "date")
);
DEFERRABLE INITIALLY IMMEDIATE permet d'indiquer que les contraintes d'intégrité seront vérifiées à la fin de la transaction par défaut.
Pour plus d'informations, n'hésitez pas à consulter la documentation de PostgreSQL à ce sujet
Après cela, utilisez la commande npm run initDB et maintenant votre base de données contient les tables supplémentaires.
Maintenant, nous allons mettre à jour notre fichier database.js pour intégrer une nouvelle méthode connect()
à notre fichier. En effet, pour les transactions, nous aurons besoin d'un client unique qui puisse exécuter une série
d'instructions pour nos transactions.
import 'dotenv/config';
import pg from 'pg';
const pgPool = new pg.Pool({
host: process.env.HOSTDB,
user: process.env.USERDB,
password: process.env.PASSWORDDB,
database: process.env.DBNAME
});
/* ----- Deuxième partie ----- */
export const pool = {
connect: async () => {
try {
const client = await pgPool.connect();
return {
query : async (query, params) => {
try {
return await client.query(query, params);
} catch (e) {
console.error(e);
throw e;
}
},
release : () => {
return client.release();
}
};
} catch (e){
console.error(e);
throw e;
}
},
query: async (query, params) => {
try {
return await pgPool.query(query, params);
} catch (e) {
console.error(e);
throw e;
}
},
end : () => {
return pgPool.end();
}
};
/* ----- Troisième partie ----- */
// Si nous fermons notre processus, nous fermerons automatiquement toutes les connexions ouvertes à la base de données
process.on('exit', () => {
pgPool.end().then(() => console.log('pool closed'));
});
Vous noterez l'apparition d'une méthode release(). Cette méthode est très importante ! En effet, la pool ne peut
générer qu'un nombre limité de clients (pour éviter de surcharger de connexions la base de données). Quand on demande de
récupérer un client avec la méthode connect(), ce dernier n'est plus géré automatiquement (comme avec pool.query()).
Il faudra donc le libérer avec la méthode release() pour que la pool puisse le supprimer ou le réutiliser.
Vous verrez donc régulièrement un appel à cette méthode dans un bloc finally pour s'assurer de la libération du client.
Etant donné que les nouveaux modèles, contrôleurs et routeurs n’incluront pas toutes les méthodes d’un CRUD (le but étant seulement de montrer la gestion d’une transaction) et qu’ils se calquent fortement sur les fichiers précédents, vous n’êtes pas obligés de les faire vous-mêmes (cependant, c’est un bon exercice). Voici les fichiers et leur contenu :
import {createPurchase} from "../model/purchase.js";
import {pool} from "../database/database.js";
export const postPurchase = async (req, res) => {
try {
await createPurchase(pool, req.val, req.body.client);
res.sendStatus(201);
} catch (e) {
console.error(e);
res.sendStatus(500);
}
};
export const purchaseWithRegistration = async (req, res) => {
let SQLClient;
try {
//TODO
} catch (err) {
//TODO
/*
Erreur avec la base de données
1. vérifier si on a un client SQL. Si oui, il faut effectuer un ROLLBACK
1.1 Capturer une éventuelle erreur durant le ROLLBACK
1.2 Dans tous les cas, envoyer une réponse à la requête HTTP
2. Dans tous les cas, vérifier si on a bien un client SQL et si c'est le cas, procéder à sa libération
*/
}
};
export const createPurchase = async (SQLClient, {articleID, quantity}, clientID) => {
const {rows} = await SQLClient.query(
"INSERT INTO purchase(product_id, client_id, quantity) VALUES ($1, $2, $3)",
[articleID, clientID, quantity]
);
return rows;
};
export const createUser = async (SQLClient, {name, firstname, address, email, password}) => {
const {rows} = await SQLClient.query(
"INSERT INTO client(name, firstname, address, email, password) VALUES ($1, $2, $3, $4, $5) RETURNING id",
[
name,
firstname,
address,
email,
password
]
);
return rows[0];
};
import Router from 'express';
import {postPurchase, purchaseWithRegistration} from "../controler/purchase.js";
const router = new Router();
router.post("/", postPurchase);
router.post("/withRegistration", purchaseWithRegistration);
export default router;
N’oubliez pas d’inclure le nouveau routeur dans le gestionnaire de route ./route/index.js.
Essayez de vous concentrer sur les cas suivants :
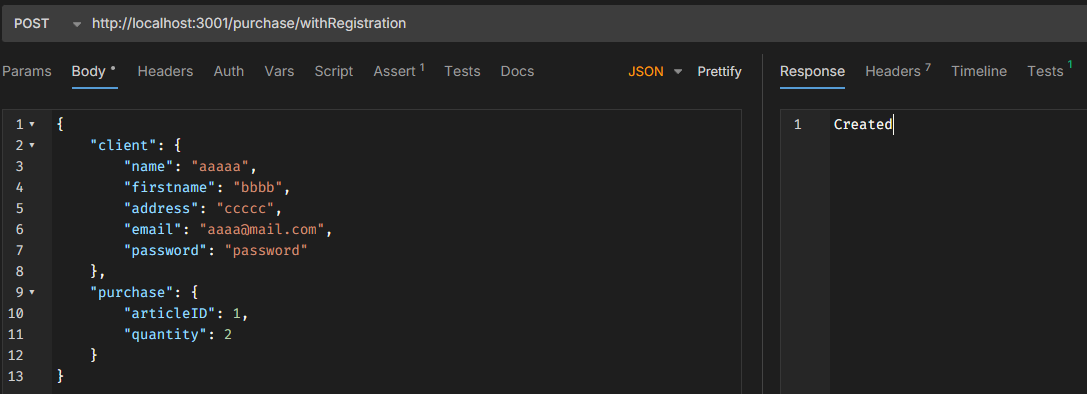
- L’opération doit ajouter un achat et un nouveau client dans une transaction
- La route pour cette opération sera
/purchase/withRegistration(méthodePOST) - Utilisez un try/catch pour capturer des éventuelles erreurs
- N’oubliez pas de Rollback/Commit et d’envoyer une réponse adéquate
Quand vous aurez fini, vous pouvez consulter la solution. Il existe plusieurs implémentations possibles, le but étant d’avoir une solution pour les étudiants qui bloquent ou qui souhaitent voir une autre approche possible.
Solution
import {createUser} from "../model/client.js";
import {createPurchase} from "../model/purchase.js";
import {pool} from "../database/database.js";
export const purchaseWithRegistration = async (req, res) => {
let SQLClient;
try {
SQLClient = await pool.connect();
await SQLClient.query("BEGIN");
const {id: clientID} = await createUser(SQLClient, req.body.client);
const {articleID, quantity} = req.body.purchase;
await createPurchase(SQLClient, {articleID, quantity}, clientID);
await SQLClient.query("COMMIT");
res.sendStatus(201);
} catch (err) {
console.error(err);
try {
//1. vérifier si on a un client SQL. Si oui, il faut effectuer un ROLLBACK
if(SQLClient){
await SQLClient.query("ROLLBACK");
}
} catch (err) {
//1.1 Capturer une éventuelle erreur durant le ROLLBACK
console.error(err);
} finally {
//1.2 Dans tous les cas, envoyer une réponse à la requête HTTP
res.sendStatus(500);
}
} finally {
//2. Dans tous les cas, vérifier si on a bien un client SQL et si c'est le cas, procéder à sa libération
if(SQLClient){
SQLClient.release();
}
}
};
import {Router} from 'express';
import {default as productRouter} from './product.js';
import {default as purchaseRouter} from './purchase.js';
const router = Router();
router.use('/product', productRouter);
router.use('/purchase', purchaseRouter);
export default router;
Et voici le résultat dans Postman :